Piano / Note name
Tap a note on the score: a keyboard names it and plays it.
Now in beta
Page Turner turns your scores into smart practice surfaces. It hears you play and turns the page for you.
It suggests fingerings tuned to your hand, writes the harmonic analysis straight onto the score, and answers questions about the piece through a specialized musical agent.
Its library engine recognizes each score automatically: composer, work, catalogue number, movement, key, form, instrumentation and year of composition. Every PDF becomes a score Page Turner can read, organize, analyze and annotate, instead of just a file in a folder.
When a passage keeps slipping, Lock Mode keeps you there: the exact bars, no scrolling ahead, no social media, no distractions until the passage is secure.
Import & library
Import PDFs.Import scans.Import MusicXML.
Or pull in another app's whole library at once. Each scan is cleaned up and engraved into a smart score you can analyze, transpose and compute on.
The library finds the composer, movements, key, form and metadata automatically. Everything backs up to iCloud and follows you across devices.
Scanning
The scanner is Apple's own — the document scanner already on your iPad. What happens next is ours: a warping pass flattens the photo into a clean page, optical music recognition reads the notes off it, and the converter writes the result as MusicXML.
It reads the title block too — composer, work, opus — so the scan files itself under its own name. A photo of paper becomes a score you can play, transpose, analyze and follow.
Score Agent
Ask for a close analysis of form and harmony, a practice plan for the hard bars, or the story behind the music. The Score Agent reads the notes on the page, so the answer is about your score, the bar you are on.
Key, form and Roman numerals are computed from the score and written onto the engraving. Historical and analytic claims carry citations you can open.
Coming soon An agent that acts on the whole app. “Organize my library.” “Build me a collection.” “Split this score into movements.” One prompt, and it does it. It can even set practice deadlines with the Coach.
Built from books, papers and pedagogy trusted by musicians.
A curated index of 10,000+ scholarly sources, extended by live search across millions of academic records when an answer needs more. Every citation is retrieved at question time and linked back to its origin. The agent’s practice guidance draws on the Alexander Technique.
Harmony written onto the score
The piece is parsed for key and form, then Roman numerals are computed onto the engraving. The harmony engine is grounded in Goldman’s harmony treatise. The excerpt below comes straight from the same pipeline the app runs.

Sources stay attached to the piece
When the chat cites a source, Page Turner files it in the piece bibliography, attached to the score. The links are there when you come back.
Smart tools
Smart annotations understand the notation: dynamics, hairpins and markings become editable objects on the staff. Auto-fingering suggests fingerings for a passage and tunes them to your own reach: scan your hand once, and the engine measures the span it can play.
The toolkit
Practice tools and page editors, one tap away.
Tap a note on the score: a keyboard names it and plays it.
A clean reference pitch. A 440, or yours.
Any MusicXML score, up or down, in a tap.
Reorder the pages of a PDF into the copy you perform from.
Flattens a phone-photographed score and cleans the page back to black on white.
Movements and sections detected on the pages automatically. Tap one to land there.
Open pieces group into tabs by composer, period or form, or any group you make.
Sample-accurate, with accents and meter. It mixes with your audio instead of cutting it.
Coming soon A smart metronome that reuses the Live Tracker's time-warping model: it understands your rubato inside the phrase, then puts you back on track at the phrase ends.
Control options
Hands on the keys or hands free, on stage or in the practice room.
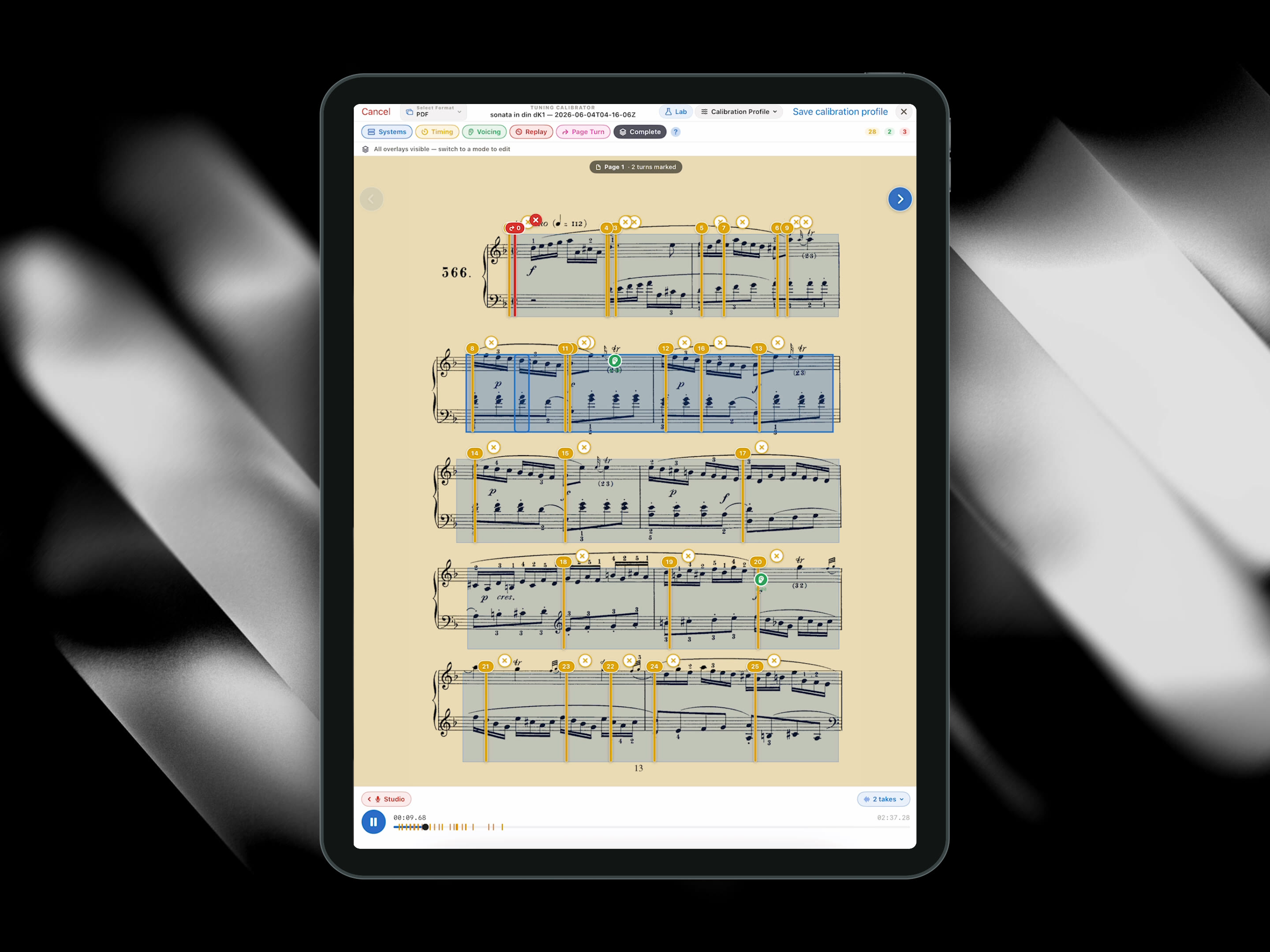
Live Tracker
The app listens while you play. Rubato, repeats, hesitations: it stays with you.
Record yourself once.Place a few anchors.Play.The score follows.
An engraved score works out of the box. A scanned PDF starts in the System Calibrator: you tie the page to the sound once, and the tracker takes it from there.
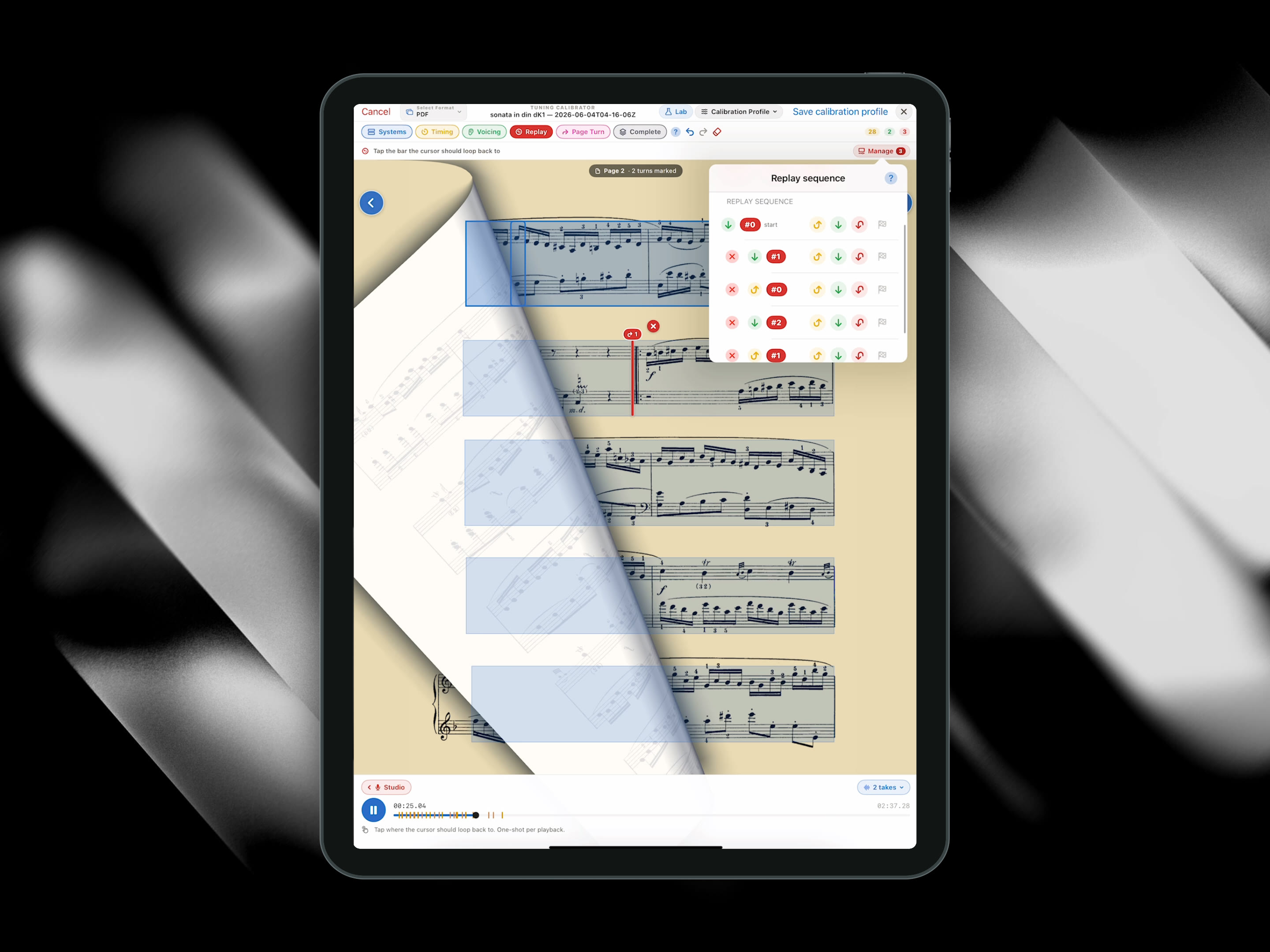
Under the hood
Ten times a second, the Live Tracker hears your playing as a fingerprint of twelve pitches and matches it against a map built ahead of time from the score itself. The bright valley in that map is the line of the music you are on. It even weighs the paths it rejects.
Built on open standards — your scores stay portable MusicXML and MEI, never locked to us.
Practice
Working a hard passage? Tap any bar and the Live Tracker snaps to you. The manual anchor stays in reach the whole session.
Concert
On stage, the Live Tracker runs forward-only. Just the next page, on time.
On the roadmap
The Live Tracker already follows you. The Coach is where it goes next: when too many slips pile up in one section, it offers a short, focused session on just those bars.
You choose to lock in: which bars, how long, what stays locked. Social apps and score navigation hold until the time runs out, or you nail it.
I caught a few slips around system 2, page 3, bars 11 to 14. Want a focused session on just those bars? Social apps and score navigation stay locked, for a set time, or until you nail it.
Page Turner is built independently by Élie Simard.
Élie holds a master’s degree in classical piano at University of Montreal and a college diploma in software development. Page Turner comes from the real problems of working from scores on iPad: page turns, scans, annotations, score libraries, harmonic analysis, lieder translation, fingerings, focused practice and performance.
Support the public launch.
Your support helps cover testing, hosting, launch visuals and the final push from TestFlight to public release.

Score Agent